第一步:定义数据源ds1,如下:
SELECT 订单明细.单价,订单明细.数量,订单.货主地区 FROM 订单,订单明细 WHERE 订单.订单ID = 订单明细.订单ID
第二步:设计表样,定义表达式
其中:
A2单元格输入表达式:=ds1.group(货主地区.false),设置为纵向扩展
B2单元格输入表达式:=ds.count()
C2单元格输入表达式:=b2/b3,设置为百分数格式,并保留2位小数
D2单元格输入表达式:=ds.sum(数量*单价),设置为人民币格式,并保留2位小数
E2单元格输入表达式:=d2/d3,设置为百分数格式,并保留2位小数
B3单元格输入表达式:=sum(b2{})
D3单元格输入表达式:=sum(d2{}),设置为人民币格式,并保留2位小数
第三步:保存预览
这是一个比较简单的行间运算例子,该例子要求报表引擎在解析报表时,能够先解析表达式,判断出B2格和D2格的占比表达式用到了B3格和D3格,从而先计算B3格和D3格,然后再计算C2格和E2格。
对于很多引用第三方表达式解析器(如BeanShell)的报表工具来说,就无法智能的判断运算优先级了。因此,对于那类报表工具来说,看起来很简单的占比报表,实现起来却很麻烦。
第一步:定义数据源ds1,如下所示:
SELECT EMPLOYEE.EMPNAME,订单明细.数量,订单明细.单价 FROM EMPLOYEE,订单,订单明细 WHERE 订单.订单ID = 订单明细.订单ID AND EMPLOYEE.EMPID = 订单.雇员ID
第二步:设计表样,定义表达式

其中:
A2单元格输入表达式:= &B2,左主格设置为C2
B2单元格输入表达式:=ds1.Group(EMPNAME,false,,,sum(数量*单价),true),左主格设置为A0,并设置为纵向扩展。
C2单元格输入表达式:=ds1.sum(数量*单价),设置为人民币格式,并保留2位小数
D2单元格输入表达式:=c2[1]-c2,设置为人民币格式,并保留2位小数
第三步:保存预览
这个例子中用到了绝对层次坐标和根格的概念。
第一步:定义数据源ds1,如下所示:
SELECT 订单.订购日期,订单明细.单价,订单明细.数量 FROM 订单,订单明细 WHERE 订单.订单ID = 订单明细.订单ID AND 订单.订购日期 is not null
第二步:设计表样,定义表达式

其中:
A2单元格输入表达式:=ds1.group(year(订购日期),false),设置为纵向扩展
B2单元格输入表达式:=ds1.group(month(订购日期),false) ,并设置为纵向扩展。
C2单元格输入表达式:=ds1.sum(数量*单价),设置为人民币格式,并保留2位小数
D2单元格输入表达式:=C2/C2[-1] ,设置为数字百分比格式,并保留2位小数
第三步:保存预览
这个例子中用到了位移坐标的概念,并且采用了坐标缺省表示法。练习:如果不采用坐标缺省表示法该如何实现?答案如下:

把刚才的例子进一步深化,刚才的例子只是当前月与紧邻的上个月的数据的环比,如果要与上一个年度的同一个月的数据进行对比该如何做呢? 做法如下:

其中:
E2单元格输入表达式:=C2/C2[A2:-1]{B2=$B2} ,设置为数字百分比格式,并保留2位小数
第三步:保存预览
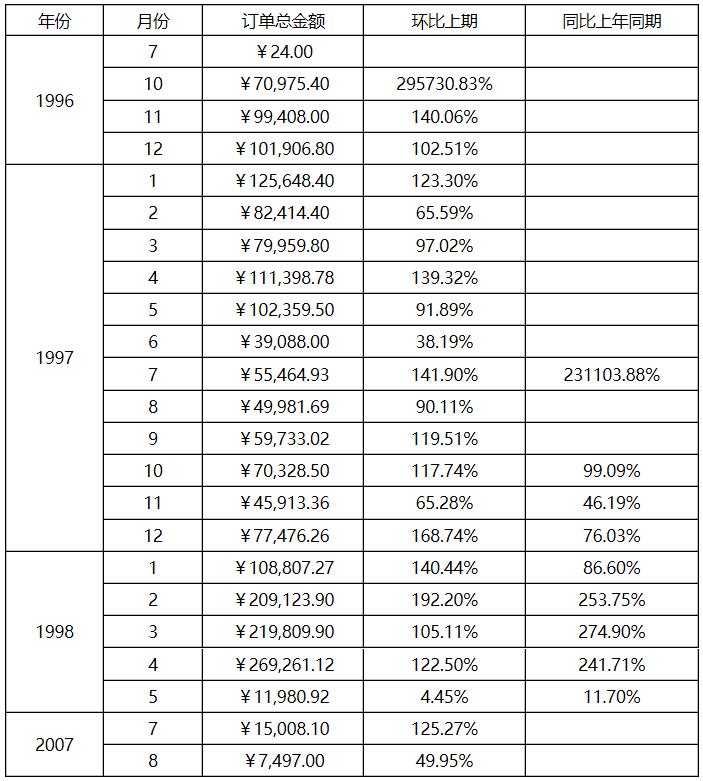
这个例子中用到了位移坐标的概念,并且采用了坐标缺省表示法; 还用到了$运算符,$运算符的书写规则如下:$Cellx,其含义是在格集表达式中指代当前格的Cellx主格(请培训人员在此讲解几个使用$运算符的例子以加深理解)
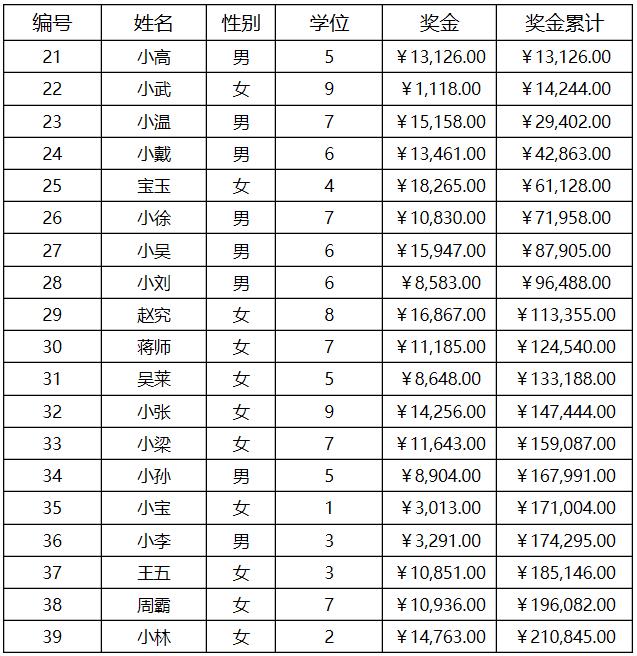
第一步:定义数据源,如下所示:
ds1:SELECT EMPLOYEE.EMPID,EMPLOYEE.EMPNAME,EMPLOYEE.SEX,EMPLOYEE.DEGREE,EMPLOYEE.BONUS FROM EMPLOYEE ds2:SELECT DEGREE.ID,DEGREE.NAME FROM DEGREE
第二步:设计表样,定义表达式

其中:
A2单元格输入表达式:=ds1.Select(EMPID,false,,toint(EMPID)),设置为纵向扩展
B2单元格输入表达式:=ds1.EMPNAME
C2单元格输入表达式:=ds1.SEX,显示值表达式为:=if(@value=="1","男","女")
D2单元格输入表达式:=ds1.DEGREE,显示值表示设置为:=ds2.getone(NAME,ID==@value)
E2单元格输入表达式:=ds1.BONUS,设置为人民币格式,并保留2位小数
F2单元格输入表达式:= e2+f2[-1] ,设置为人民币格式,并保留2位小数
第三步:保存预览
分组汇总与统计我们在前面讲述分组报表的时候已经讲过了,这里给大家一定的时间再次温习一下《入门教程-分组式报表》中的第3节,为我们下面要讲的条件汇总做好准备。
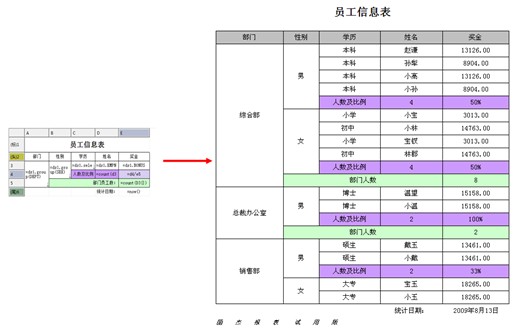
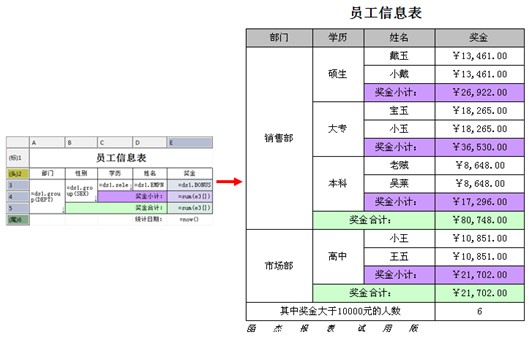
第一步:定义数据源,如下所示:
ds1:SELECT DEPT,SEX, DEGREE, BONUS, EMPNAME FROM EMPLOYEE where dept in (1,3) ds2:SELECT DEGREE.ID,DEGREE.NAME FROM DEGREE ds3:SELECT DEPT.DEPTID,DEPT.DEPTNAME FROM DEPT
第二步:设计表样,定义表达式
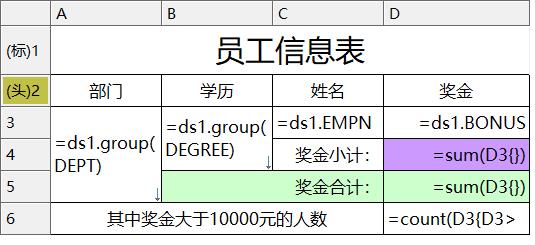
其中:
A3单元格输入表达式:=ds1.group(DEPT),显示值表示设置为:= ds3.getone(DEPTNAME,DEPTID==@value),设置为纵向扩展
B3单元格输入表达式:=ds1.group(DEGREE) ,显示值表示设置为:= ds2.getone(name,id==@value) ,设置为纵向扩展。
C3单元格输入表达式:= ds1.select(EMPNAME) ,设置为纵向扩展
D3单元格输入表达式:=ds1.BONUS,设置为人民币格式,并保留2位小数
D4单元格输入表达式:= sum(D3{}) ,设置为人民币格式,并保留2位小数
D5单元格输入表达式:= sum(D3{}) ,设置为人民币格式,并保留2位小数
D6单元格输入表达式:= count(D3{D3>10000})
第三步:保存预览
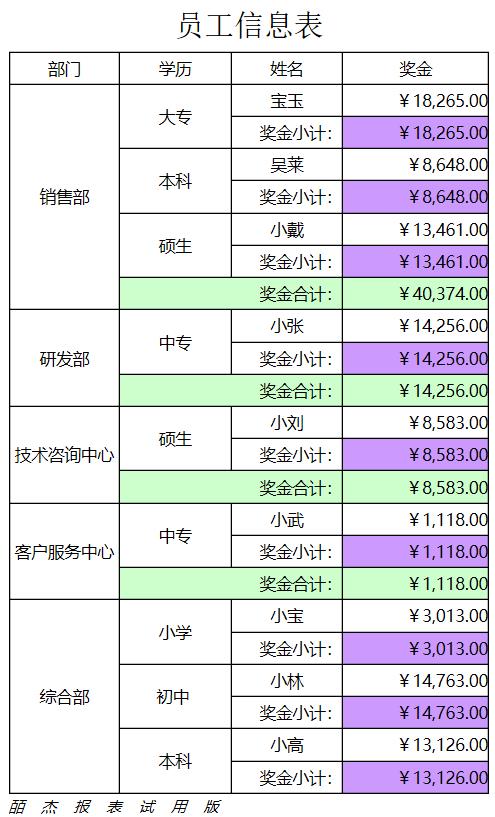
这个例子中用到了单元格集合的概念,一个单元格的扩展集合的书写形式如下:
Cellx[层次坐标或者位移坐标]{条件表达式}
例如:
sum(D3{}) 表示求D3单元格集合中所有单元格的数值之和
count(D3{D3>10000}) 表示是统计D3单元格集合中数值高于10000的个数
组内排名
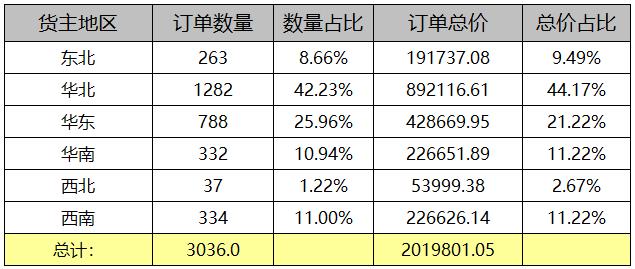
第一步:定义数据源ds1,如下所示:
SELECT 订单.货主地区,订单.货主城市,订单明细.单价,订单明细.数量 FROM 订单,订单明细 WHERE 订单.订单ID = 订单明细.订单ID
第二步:设计表样,定义表达式

其中:
A2单元格输入表达式:=ds1.group(货主地区),设置为纵向扩展
B2单元格输入表达式:=ds1.group(货主城市) ,设置为纵向扩展。
C2单元格输入表达式:=ds1.sum(单价*数量) ,设置为人民币格式,并保留2位小数
D2单元格输入表达式:=rank(C2,C2[A2]{})
第三步:保存预览
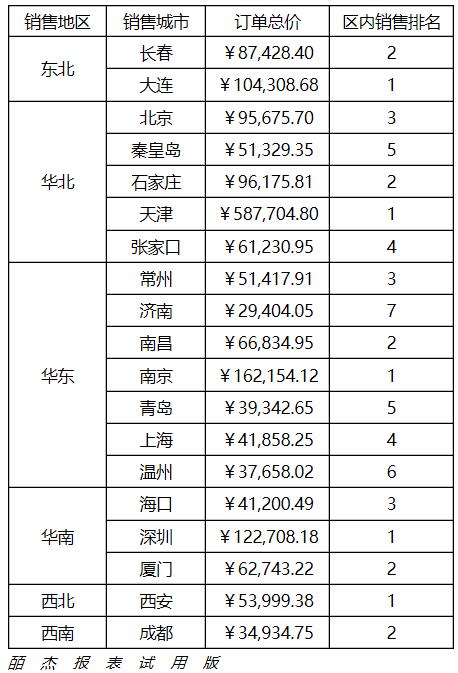
组间排名
如果统计排名时不光统计每一地区内的排名,还要统计总的排名,该如何做呢?
第一步:在最后增加一列,如下图所示:

第二步:为E2定义表达式如下:
E2单元格输入表达式:=rank(C2,C2[A0]{})
第三步:保存预览
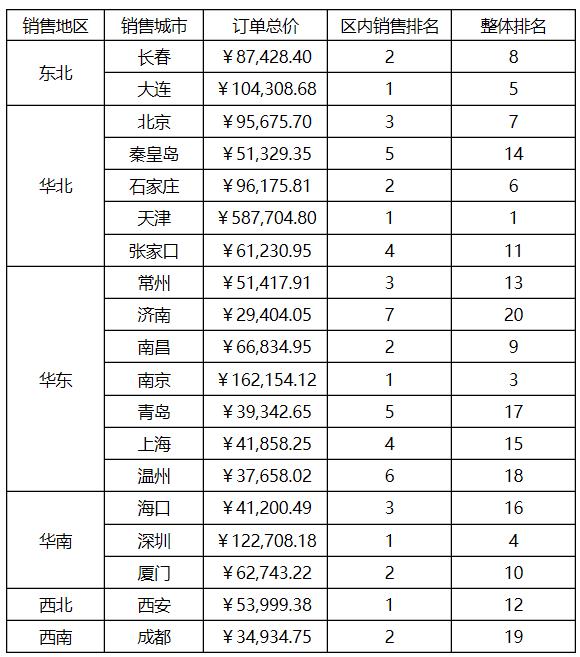
这个例子中用到了扩展单元格集合的概念,各位想想如果不用排名函数,有没有其他方式能实现组内、组间排名呢?答案是肯定的,可以考虑用count函数来实现排名,具体做法如下:
用count(C2[A2]{C2>$C2})+1来代替rank(c2,C2[A2]{})
用 count(C2[A0]{C2>$C2})+1来代替rank(c2,C2[A0]{})
可见只要熟练掌握了扩展的思想,以及扩展出来的单元的获取方式,就可以很灵活的进行处理。
组内序号
第一步:定义数据源ds1,如下所示:
SELECT 订单.货主地区,订单.货主城市,订单明细.单价,订单明细.数量 FROM 订单,订单明细 WHERE 订单.订单ID = 订单明细.订单ID
第二步:设计表样,定义表达式

其中:
A2单元格输入表达式:=&C2 ,左主格设置为c2
B2单元格输入表达式:=ds1.group(货主地区) ,左主格设置为A0,设置为纵向扩展。
C2单元格输入表达式:=ds1.group(货主城市) ,设置为纵向扩展
D2单元格输入表达式:=ds1.select(单价)
D2单元格输入表达式:=ds1.数量
第三步:保存预览
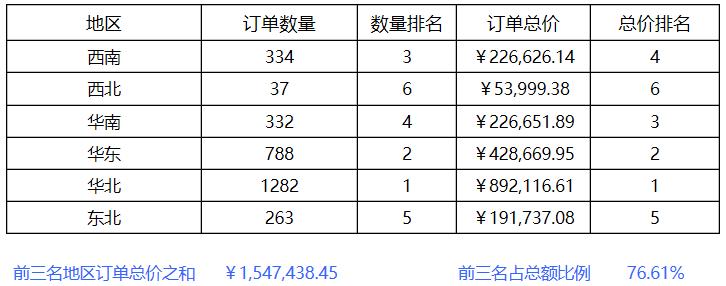
第一步:定义数据源ds1,如下:
SELECT 订单.货主地区,订单明细.数量,订单明细.单价 FROM 订单,订单明细 WHERE 订单明细.订单ID = 订单.订单ID
第二步:设计表样,定义表达式

其中:
A2单元格输入表达式:=ds1.group(货主地区,true) ,设置为纵向扩展
B2单元格输入表达式:= ds1.count()。
C2单元格输入表达式:= rank(b2,b2[a0]{})
D2单元格输入表达式:= ds1.sum(单价 * 数量)
E2单元格输入表达式:=rank(d2,d2[a0]{})
B4单元格输入表达式:= sum(D2{E2<=3})
E4单元格输入表达式:= B4/sum(D2{})
第三步:保存预览